Company
Jan 30, 2018
Recap: Aptible January 2018 Quarterly Product Update Webinar
Recap: Aptible January 2018 Quarterly Product Update Webinar

Chas Ballew
Product & Engineering
SHARE
SHARE
SHARE
Every quarter, we host a webinar to share everything that’s new with Enclave and Gridiron.
In case you missed it, you can watch a recording of our January webinar below. You can also grab the transcript and the slide deck in our resources section. We provide a full recap of the event in this post.
January 2018 Quarterly Product Update Webinar
Webinar Recap
Meltdown and Spectre
We kicked off the webinar with a panel on Meltdown and Spectre, to discuss on how we protect our customers as in the event of disclosed vulnerabilities. We also did a deep dive into the ways that Enclave is architected for security more generally, with an emphasis on isolation based on trust levels. CTO Frank Macreery and Lead Enclave Developer Thomas Orozco discussed these topics and more in a conversation moderated by Web Security Advocate Elissa Shevinsky.
Meltdown and Spectre aren’t the worst vulnerabilities, but they are unique because they have a wide impact. Specifically, Meltdown and Spectre are a design flaw in CPUs that affects modern Intel processors as well as other processors that are used in everything from laptops to mobile devices. Meltdown uses speculative execution to leak kernel data. Spectre can also be used to leak information from the kernel. It’s trickier to exploit but also more difficult to mitigate.
Meltdown can be easy to exploit and those exploits are difficult to detect. Meltdown exploits privilege escalation paths, which makes it particularly relevant for cloud computing infrastructure like Aptible.
There are two general pathways to exploit Meltdown. The first is an attacker can gain access to data run by your peers (on same instance as you.) Aptible protects against this on Enclave by requiring that all sensitive workloads are isolated on dedicated-tenancy stacks (which are not shared with other customers).
The other way is to attack Enclave itself. If you look at Enclave, anyone on the internet can potentially open up an account on a shared environment. The way we protect the risk of access to Enclave is by separating our riskiest systems from our most sensitive environment variables that are required to administer Aptible.
We’ve put together a diagram and slide deck showing how we think about trust level, isolation, and threats. We isolate the riskiest components from the most sensitive and privileged data. Our CTO Frank Macreery wrote a blog post on how the Aptible team responded to Meltdown and Spectre. For an even deeper dive into these details, we recommend watching the webinar or reading the webinar transcript.
Meltdown Mitigation
The steps for the Meltdown mitigation were fairly extensive. We began our patching process with the most high risk instances, which are shared-tenancy instances. (We love our customers but treat all applications as potentially untrusted by nature.) Then we moved onto dedicated tenancy stacks. As a final step we scheduled maintenance windows with customers to restart databases and make sure all instances were patched against Meltdown. We completed on Jan 9th, five days after we began.
Takeaways
There’s a lot to be learned from these vulnerabilities, and there are important lessons that our customers can and should apply to any potential security risk.
You always want to start your security process by identifying abstract threats i.e. where you are vulnerable and how you can architect to protect against those vulnerabilities.
Threats are individual. The threats to your company may be different than the threats that we face at Aptible.
You want to figure out what services you depend on (that are the biggest threats) and how to architect to isolate and protect against those threats.
Threats aren’t always abstract. Whenever a new major vulnerability emerges (Meltdown, for example) you want to assess how that fits into your security model and how you need to respond to it. And this is a process that should be ongoing over time.
The Enclave infrastructure wasn’t built overnight—it was an iterative process. The diagram that we’ve shown in the slide deck is the result of an accumulation of updates and improvements since 2013.
Enclave Metric Drains
We released a new feature: Metric Drains. Metric Drains help you monitor the performance of your containers. Container Metrics are captured every 30 seconds. They are routed every 15 seconds to the destination of your choice. Currently, that includes InfluxDB (both hosted on Enclave or hosted by InfluxData) and Datadog. More third party providers to come in the future—feedback welcome.
We’ve had a lot of requests around metrics retention. Using Metric Drains, you can retain the metrics for as long as you want, and,you gain ownership of your metrics. You can incorporate them into dashboards, for example, to better understand your applications.
Metric drains are functionally similar to Log Drains except for metrics. What’s captured?
Metrics:
Running Status
CPU Usage
Memory Usage & Limit
Disk IO
Disk Usage & Limit (DB Only.)
If you want to start capturing performance metrics, check out our documentation on Metric Drains.
Other Enclave Updates
Managed HIDS
Managed HIDS is now generally available. On a weekly basis, you get audit ready PDF + CSV reports.This satisfies compliance requirements for intrusion detection. Free for shared tenancy stacks and $0.02 / GB / hour for dedicated tenancy stacks.
VPC Peers and VPN Tunnels
Connect to any AWS VPC via a peering connection. No maintenance and 100% free. If you have your own VPC, this is convenient. The downside is this only works for AWS, which is where VPN tunnels come in as another option. VPN tunnels connect to any VPN network. Requires a VPN gateway. $99 / VPN connection.
For setup, just contact Aptible support at contact.aptible.com. Once setup, connection details are visible in the dashboard.
Additional Enclave Features
The Enclave CLI now supports JSON output. JSON output provides enhanced scriptability.
The DB:create command now supports picking a version.
Restored instances of a MongoDB replica set will no longer attempt to join the existing replica set.
Every quarter, we host a webinar to share everything that’s new with Enclave and Gridiron.
In case you missed it, you can watch a recording of our January webinar below. You can also grab the transcript and the slide deck in our resources section. We provide a full recap of the event in this post.
January 2018 Quarterly Product Update Webinar
Webinar Recap
Meltdown and Spectre
We kicked off the webinar with a panel on Meltdown and Spectre, to discuss on how we protect our customers as in the event of disclosed vulnerabilities. We also did a deep dive into the ways that Enclave is architected for security more generally, with an emphasis on isolation based on trust levels. CTO Frank Macreery and Lead Enclave Developer Thomas Orozco discussed these topics and more in a conversation moderated by Web Security Advocate Elissa Shevinsky.
Meltdown and Spectre aren’t the worst vulnerabilities, but they are unique because they have a wide impact. Specifically, Meltdown and Spectre are a design flaw in CPUs that affects modern Intel processors as well as other processors that are used in everything from laptops to mobile devices. Meltdown uses speculative execution to leak kernel data. Spectre can also be used to leak information from the kernel. It’s trickier to exploit but also more difficult to mitigate.
Meltdown can be easy to exploit and those exploits are difficult to detect. Meltdown exploits privilege escalation paths, which makes it particularly relevant for cloud computing infrastructure like Aptible.
There are two general pathways to exploit Meltdown. The first is an attacker can gain access to data run by your peers (on same instance as you.) Aptible protects against this on Enclave by requiring that all sensitive workloads are isolated on dedicated-tenancy stacks (which are not shared with other customers).
The other way is to attack Enclave itself. If you look at Enclave, anyone on the internet can potentially open up an account on a shared environment. The way we protect the risk of access to Enclave is by separating our riskiest systems from our most sensitive environment variables that are required to administer Aptible.
We’ve put together a diagram and slide deck showing how we think about trust level, isolation, and threats. We isolate the riskiest components from the most sensitive and privileged data. Our CTO Frank Macreery wrote a blog post on how the Aptible team responded to Meltdown and Spectre. For an even deeper dive into these details, we recommend watching the webinar or reading the webinar transcript.
Meltdown Mitigation
The steps for the Meltdown mitigation were fairly extensive. We began our patching process with the most high risk instances, which are shared-tenancy instances. (We love our customers but treat all applications as potentially untrusted by nature.) Then we moved onto dedicated tenancy stacks. As a final step we scheduled maintenance windows with customers to restart databases and make sure all instances were patched against Meltdown. We completed on Jan 9th, five days after we began.
Takeaways
There’s a lot to be learned from these vulnerabilities, and there are important lessons that our customers can and should apply to any potential security risk.
You always want to start your security process by identifying abstract threats i.e. where you are vulnerable and how you can architect to protect against those vulnerabilities.
Threats are individual. The threats to your company may be different than the threats that we face at Aptible.
You want to figure out what services you depend on (that are the biggest threats) and how to architect to isolate and protect against those threats.
Threats aren’t always abstract. Whenever a new major vulnerability emerges (Meltdown, for example) you want to assess how that fits into your security model and how you need to respond to it. And this is a process that should be ongoing over time.
The Enclave infrastructure wasn’t built overnight—it was an iterative process. The diagram that we’ve shown in the slide deck is the result of an accumulation of updates and improvements since 2013.
Enclave Metric Drains
We released a new feature: Metric Drains. Metric Drains help you monitor the performance of your containers. Container Metrics are captured every 30 seconds. They are routed every 15 seconds to the destination of your choice. Currently, that includes InfluxDB (both hosted on Enclave or hosted by InfluxData) and Datadog. More third party providers to come in the future—feedback welcome.
We’ve had a lot of requests around metrics retention. Using Metric Drains, you can retain the metrics for as long as you want, and,you gain ownership of your metrics. You can incorporate them into dashboards, for example, to better understand your applications.
Metric drains are functionally similar to Log Drains except for metrics. What’s captured?
Metrics:
Running Status
CPU Usage
Memory Usage & Limit
Disk IO
Disk Usage & Limit (DB Only.)
If you want to start capturing performance metrics, check out our documentation on Metric Drains.
Other Enclave Updates
Managed HIDS
Managed HIDS is now generally available. On a weekly basis, you get audit ready PDF + CSV reports.This satisfies compliance requirements for intrusion detection. Free for shared tenancy stacks and $0.02 / GB / hour for dedicated tenancy stacks.
VPC Peers and VPN Tunnels
Connect to any AWS VPC via a peering connection. No maintenance and 100% free. If you have your own VPC, this is convenient. The downside is this only works for AWS, which is where VPN tunnels come in as another option. VPN tunnels connect to any VPN network. Requires a VPN gateway. $99 / VPN connection.
For setup, just contact Aptible support at contact.aptible.com. Once setup, connection details are visible in the dashboard.
Additional Enclave Features
The Enclave CLI now supports JSON output. JSON output provides enhanced scriptability.
The DB:create command now supports picking a version.
Restored instances of a MongoDB replica set will no longer attempt to join the existing replica set.
Every quarter, we host a webinar to share everything that’s new with Enclave and Gridiron.
In case you missed it, you can watch a recording of our January webinar below. You can also grab the transcript and the slide deck in our resources section. We provide a full recap of the event in this post.
January 2018 Quarterly Product Update Webinar
Webinar Recap
Meltdown and Spectre
We kicked off the webinar with a panel on Meltdown and Spectre, to discuss on how we protect our customers as in the event of disclosed vulnerabilities. We also did a deep dive into the ways that Enclave is architected for security more generally, with an emphasis on isolation based on trust levels. CTO Frank Macreery and Lead Enclave Developer Thomas Orozco discussed these topics and more in a conversation moderated by Web Security Advocate Elissa Shevinsky.
Meltdown and Spectre aren’t the worst vulnerabilities, but they are unique because they have a wide impact. Specifically, Meltdown and Spectre are a design flaw in CPUs that affects modern Intel processors as well as other processors that are used in everything from laptops to mobile devices. Meltdown uses speculative execution to leak kernel data. Spectre can also be used to leak information from the kernel. It’s trickier to exploit but also more difficult to mitigate.
Meltdown can be easy to exploit and those exploits are difficult to detect. Meltdown exploits privilege escalation paths, which makes it particularly relevant for cloud computing infrastructure like Aptible.
There are two general pathways to exploit Meltdown. The first is an attacker can gain access to data run by your peers (on same instance as you.) Aptible protects against this on Enclave by requiring that all sensitive workloads are isolated on dedicated-tenancy stacks (which are not shared with other customers).
The other way is to attack Enclave itself. If you look at Enclave, anyone on the internet can potentially open up an account on a shared environment. The way we protect the risk of access to Enclave is by separating our riskiest systems from our most sensitive environment variables that are required to administer Aptible.
We’ve put together a diagram and slide deck showing how we think about trust level, isolation, and threats. We isolate the riskiest components from the most sensitive and privileged data. Our CTO Frank Macreery wrote a blog post on how the Aptible team responded to Meltdown and Spectre. For an even deeper dive into these details, we recommend watching the webinar or reading the webinar transcript.
Meltdown Mitigation
The steps for the Meltdown mitigation were fairly extensive. We began our patching process with the most high risk instances, which are shared-tenancy instances. (We love our customers but treat all applications as potentially untrusted by nature.) Then we moved onto dedicated tenancy stacks. As a final step we scheduled maintenance windows with customers to restart databases and make sure all instances were patched against Meltdown. We completed on Jan 9th, five days after we began.
Takeaways
There’s a lot to be learned from these vulnerabilities, and there are important lessons that our customers can and should apply to any potential security risk.
You always want to start your security process by identifying abstract threats i.e. where you are vulnerable and how you can architect to protect against those vulnerabilities.
Threats are individual. The threats to your company may be different than the threats that we face at Aptible.
You want to figure out what services you depend on (that are the biggest threats) and how to architect to isolate and protect against those threats.
Threats aren’t always abstract. Whenever a new major vulnerability emerges (Meltdown, for example) you want to assess how that fits into your security model and how you need to respond to it. And this is a process that should be ongoing over time.
The Enclave infrastructure wasn’t built overnight—it was an iterative process. The diagram that we’ve shown in the slide deck is the result of an accumulation of updates and improvements since 2013.
Enclave Metric Drains
We released a new feature: Metric Drains. Metric Drains help you monitor the performance of your containers. Container Metrics are captured every 30 seconds. They are routed every 15 seconds to the destination of your choice. Currently, that includes InfluxDB (both hosted on Enclave or hosted by InfluxData) and Datadog. More third party providers to come in the future—feedback welcome.
We’ve had a lot of requests around metrics retention. Using Metric Drains, you can retain the metrics for as long as you want, and,you gain ownership of your metrics. You can incorporate them into dashboards, for example, to better understand your applications.
Metric drains are functionally similar to Log Drains except for metrics. What’s captured?
Metrics:
Running Status
CPU Usage
Memory Usage & Limit
Disk IO
Disk Usage & Limit (DB Only.)
If you want to start capturing performance metrics, check out our documentation on Metric Drains.
Other Enclave Updates
Managed HIDS
Managed HIDS is now generally available. On a weekly basis, you get audit ready PDF + CSV reports.This satisfies compliance requirements for intrusion detection. Free for shared tenancy stacks and $0.02 / GB / hour for dedicated tenancy stacks.
VPC Peers and VPN Tunnels
Connect to any AWS VPC via a peering connection. No maintenance and 100% free. If you have your own VPC, this is convenient. The downside is this only works for AWS, which is where VPN tunnels come in as another option. VPN tunnels connect to any VPN network. Requires a VPN gateway. $99 / VPN connection.
For setup, just contact Aptible support at contact.aptible.com. Once setup, connection details are visible in the dashboard.
Additional Enclave Features
The Enclave CLI now supports JSON output. JSON output provides enhanced scriptability.
The DB:create command now supports picking a version.
Restored instances of a MongoDB replica set will no longer attempt to join the existing replica set.
Every quarter, we host a webinar to share everything that’s new with Enclave and Gridiron.
In case you missed it, you can watch a recording of our January webinar below. You can also grab the transcript and the slide deck in our resources section. We provide a full recap of the event in this post.
January 2018 Quarterly Product Update Webinar
Webinar Recap
Meltdown and Spectre
We kicked off the webinar with a panel on Meltdown and Spectre, to discuss on how we protect our customers as in the event of disclosed vulnerabilities. We also did a deep dive into the ways that Enclave is architected for security more generally, with an emphasis on isolation based on trust levels. CTO Frank Macreery and Lead Enclave Developer Thomas Orozco discussed these topics and more in a conversation moderated by Web Security Advocate Elissa Shevinsky.
Meltdown and Spectre aren’t the worst vulnerabilities, but they are unique because they have a wide impact. Specifically, Meltdown and Spectre are a design flaw in CPUs that affects modern Intel processors as well as other processors that are used in everything from laptops to mobile devices. Meltdown uses speculative execution to leak kernel data. Spectre can also be used to leak information from the kernel. It’s trickier to exploit but also more difficult to mitigate.
Meltdown can be easy to exploit and those exploits are difficult to detect. Meltdown exploits privilege escalation paths, which makes it particularly relevant for cloud computing infrastructure like Aptible.
There are two general pathways to exploit Meltdown. The first is an attacker can gain access to data run by your peers (on same instance as you.) Aptible protects against this on Enclave by requiring that all sensitive workloads are isolated on dedicated-tenancy stacks (which are not shared with other customers).
The other way is to attack Enclave itself. If you look at Enclave, anyone on the internet can potentially open up an account on a shared environment. The way we protect the risk of access to Enclave is by separating our riskiest systems from our most sensitive environment variables that are required to administer Aptible.
We’ve put together a diagram and slide deck showing how we think about trust level, isolation, and threats. We isolate the riskiest components from the most sensitive and privileged data. Our CTO Frank Macreery wrote a blog post on how the Aptible team responded to Meltdown and Spectre. For an even deeper dive into these details, we recommend watching the webinar or reading the webinar transcript.
Meltdown Mitigation
The steps for the Meltdown mitigation were fairly extensive. We began our patching process with the most high risk instances, which are shared-tenancy instances. (We love our customers but treat all applications as potentially untrusted by nature.) Then we moved onto dedicated tenancy stacks. As a final step we scheduled maintenance windows with customers to restart databases and make sure all instances were patched against Meltdown. We completed on Jan 9th, five days after we began.
Takeaways
There’s a lot to be learned from these vulnerabilities, and there are important lessons that our customers can and should apply to any potential security risk.
You always want to start your security process by identifying abstract threats i.e. where you are vulnerable and how you can architect to protect against those vulnerabilities.
Threats are individual. The threats to your company may be different than the threats that we face at Aptible.
You want to figure out what services you depend on (that are the biggest threats) and how to architect to isolate and protect against those threats.
Threats aren’t always abstract. Whenever a new major vulnerability emerges (Meltdown, for example) you want to assess how that fits into your security model and how you need to respond to it. And this is a process that should be ongoing over time.
The Enclave infrastructure wasn’t built overnight—it was an iterative process. The diagram that we’ve shown in the slide deck is the result of an accumulation of updates and improvements since 2013.
Enclave Metric Drains
We released a new feature: Metric Drains. Metric Drains help you monitor the performance of your containers. Container Metrics are captured every 30 seconds. They are routed every 15 seconds to the destination of your choice. Currently, that includes InfluxDB (both hosted on Enclave or hosted by InfluxData) and Datadog. More third party providers to come in the future—feedback welcome.
We’ve had a lot of requests around metrics retention. Using Metric Drains, you can retain the metrics for as long as you want, and,you gain ownership of your metrics. You can incorporate them into dashboards, for example, to better understand your applications.
Metric drains are functionally similar to Log Drains except for metrics. What’s captured?
Metrics:
Running Status
CPU Usage
Memory Usage & Limit
Disk IO
Disk Usage & Limit (DB Only.)
If you want to start capturing performance metrics, check out our documentation on Metric Drains.
Other Enclave Updates
Managed HIDS
Managed HIDS is now generally available. On a weekly basis, you get audit ready PDF + CSV reports.This satisfies compliance requirements for intrusion detection. Free for shared tenancy stacks and $0.02 / GB / hour for dedicated tenancy stacks.
VPC Peers and VPN Tunnels
Connect to any AWS VPC via a peering connection. No maintenance and 100% free. If you have your own VPC, this is convenient. The downside is this only works for AWS, which is where VPN tunnels come in as another option. VPN tunnels connect to any VPN network. Requires a VPN gateway. $99 / VPN connection.
For setup, just contact Aptible support at contact.aptible.com. Once setup, connection details are visible in the dashboard.
Additional Enclave Features
The Enclave CLI now supports JSON output. JSON output provides enhanced scriptability.
The DB:create command now supports picking a version.
Restored instances of a MongoDB replica set will no longer attempt to join the existing replica set.
Latest From Our Blog

Thoughts & Ideas
HIPAA on PaaS: Vercel, Render, Heroku, Railway, and Aptible

Gabriella Valdes
Customer Success
Thoughts & Ideas
HIPAA on PaaS: Vercel, Render, Heroku, Railway, and Aptible
Gabriella Valdes
Customer Success
Thoughts & Ideas
HIPAA on PaaS: Vercel, Render, Heroku, Railway, and Aptible
Gabriella Valdes
Customer Success
Thoughts & Ideas
HIPAA on PaaS: Vercel, Render, Heroku, Railway, and Aptible
Gabriella Valdes
Customer Success

Company
Aptible in 2024: Year in Review

Frank Macreery
CEO
Company
Aptible in 2024: Year in Review
Frank Macreery
CEO
Company
Aptible in 2024: Year in Review
Frank Macreery
CEO
Company
Aptible in 2024: Year in Review
Frank Macreery
CEO
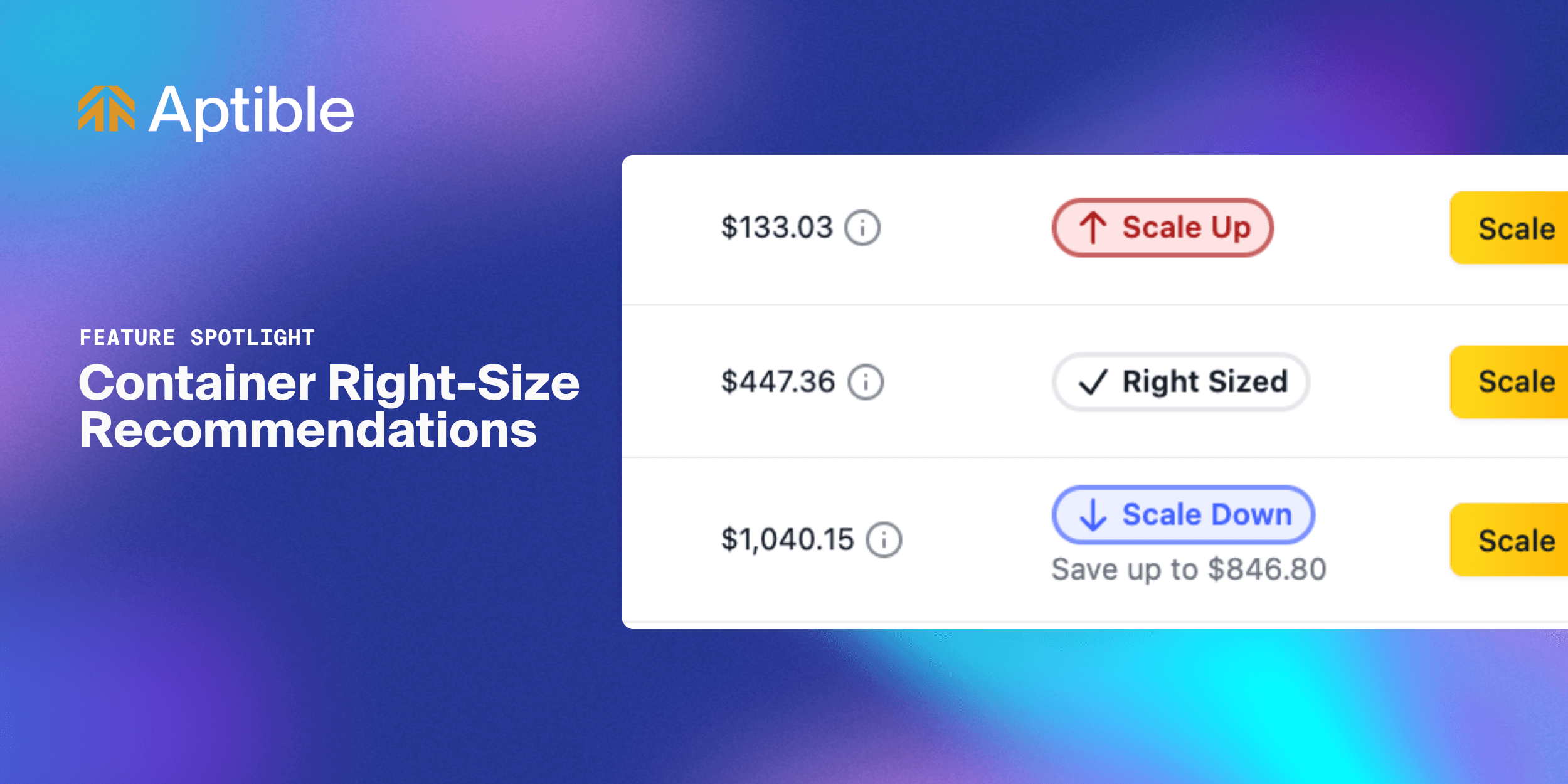
Changelog
Introducing Container Right-Size Recommendations for Apps and Databases
Gabriella Valdes
Customer Success
Changelog
Introducing Container Right-Size Recommendations for Apps and Databases
Gabriella Valdes
Customer Success
Changelog
Introducing Container Right-Size Recommendations for Apps and Databases
Gabriella Valdes
Customer Success
Changelog
Introducing Container Right-Size Recommendations for Apps and Databases
Gabriella Valdes
Customer Success



548 Market St #75826 San Francisco, CA 94104
© 2025. All rights reserved. Privacy Policy
548 Market St #75826 San Francisco, CA 94104
© 2025. All rights reserved. Privacy Policy
548 Market St #75826 San Francisco, CA 94104
© 2025. All rights reserved. Privacy Policy
548 Market St #75826 San Francisco, CA 94104
© 2025. All rights reserved. Privacy Policy